The Three Pillars of Network Monitoring: A Holistic Strategy
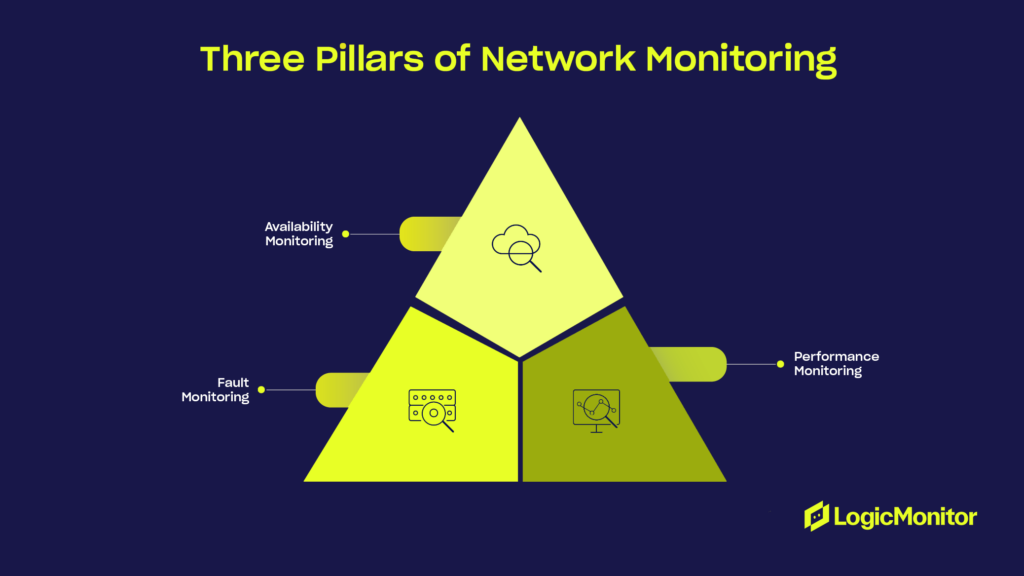
Effective network monitoring relies on fault detection, performance optimization, and availability tracking, ensuring a comprehensive view and proactive issue resolution.
To truly safeguard your infrastructure, it’s crucial to adopt a holistic strategy that covers every aspect of your network’s health and performance. This means integrating fault monitoring, performance monitoring, and availability monitoring into a comprehensive strategy. Lets discuss how a well-rounded approach to network monitoring can help you maintain resilience, optimize performance, and prevent downtime.
Think of network monitoring as a three-legged stool supported by the following essential pillars.
First Pillar: Fault Monitoring
Fault monitoring is like having a smoke detector for your network. It’s your first line of defense against potential issues, focusing on detecting errors and anomalies that could lead to disruptions or outages.
Error Detection
Continuously monitor error logs and SNMP traps: These are your network’s vital signs, providing valuable clues about potential issues, such as hardware failures, connectivity problems, or misconfigurations.
Stay ahead of firmware bugs: Don’t underestimate the impact of firmware bugs in network devices. Faulty firmware can cause unexpected performance degradation or even crashes. Regularly updating firmware is like giving your network devices a health checkup.
Pro tip: Log aggregation tools that centralize and analyze logs from all your network devices are invaluable. They can help you detect patterns that indicate a systemic issue, such as frequent port resets or protocol timeouts across multiple devices.
Automated alerts: When an error is detected, automated alerts should notify the appropriate teams, ensuring a swift response.
Role-based notifications: Make sure the right people receive the right alerts. For example, an alert about high CPU usage on a core switch should be routed to network engineers, while security-related alerts should go to the security operations center (SOC).
Pro tip: Use AI-powered alert correlation to group related alerts and reduce noise. This prevents alert fatigue and helps your team focus on the root cause of problems.
Dependency mapping
Identify the root cause: Once an issue is detected, it’s crucial to identify the root cause to prevent it from recurring. Think of it as detective work for your network.
Analyze dependencies: Dependency alert mapping helps you understand how different components in your infrastructure interact and how a failure in one area might impact others.
Pro tip: Integrate fault monitoring with your configuration management systems. This allows you to compare device settings and change logs in real time, helping you trace faults back to specific configuration changes or deployments.
Second pillar: Performance monitoring
Performance monitoring is like having a fitness tracker for your network. It’s all about tracking key performance metrics to ensure that your systems are operating at peak efficiency and delivering a seamless user experience.
Key metrics tracking
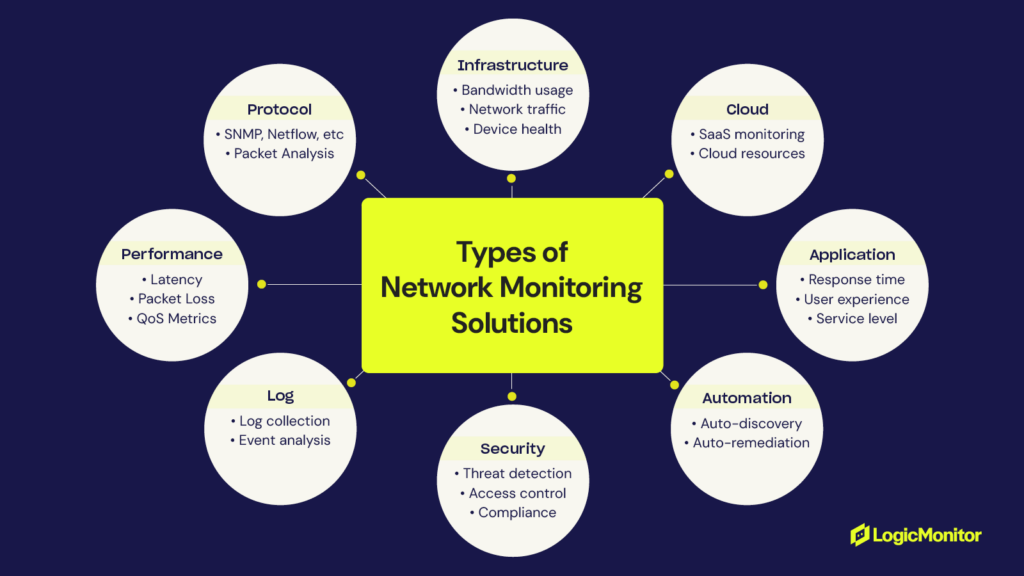
Bandwidth usage: Monitor how much bandwidth is being consumed by different applications and users. Identify any bandwidth hogs that might be impacting overall performance.
CPU utilization: Track the processing load on your devices to identify potential bottlenecks. High CPU usage can indicate that a device is struggling to keep up with demand.
Memory consumption: Ensure that your devices have enough memory to handle their workloads. Running out of memory can lead to crashes and instability.
Latency: Measure the delay in data transmission to ensure optimal application performance. High latency can cause frustrating delays for users, especially in real-time applications.
Pro tip: Implement dynamic baselining to track performance metrics in real time and adjust thresholds based on historical data. This helps you avoid false positives and focus on true anomalies.
Scalability and optimization
Identify scaling needs: Performance monitoring helps you identify when your infrastructure needs to be scaled to accommodate growing demands.
Optimize resource allocation: By monitoring resource usage, you can identify areas where resources can be optimized or redistributed to improve efficiency.
Pro tip: Use predictive analytics to forecast future resource needs based on current performance trends. This allows you to proactively plan upgrades or allocate additional resources before bottlenecks occur.
Availability monitoring is like having a reliable backup generator. It focuses on ensuring that critical resources, such as servers, databases, and applications, are available when needed, minimizing downtime and ensuring business continuity.
Uptime monitoring
Regular uptime checks: Ensure that critical systems are up and running and responding as expected. Think of it as a heartbeat monitor for your network.
Monitor at different layers: Track availability at both the application layer and the infrastructure layer to get a complete picture of system health.
Pro tip: To enhance uptime monitoring, deploy synthetic testing, where artificial requests simulate user behavior to proactively test the availability and responsiveness of your services.
Service-level agreements (SLAs) compliance
Monitor SLAs: Ensure that your infrastructure meets your contractual obligations for uptime and performance.
Track uptime and notify of potential breaches: Receive alerts when your systems are approaching an SLA violation.
Pro tip: Automate SLA reporting to provide real-time compliance data to stakeholders and proactively address potential violations.
Redundancy verification
Test failover systems: Regularly test your backup systems, such as secondary data centers and load balancers, to ensure they can take over seamlessly in case of a failure.
Ensure high availability: Effective redundancy is crucial for maintaining high availability and minimizing the impact of disruptions.
Comprehensive network monitoring architectures unify the three core pillars
A solid network monitoring setup brings together fault monitoring, performance monitoring, and availability monitoring for a unified, reliable way to manage your network. By combining these three key pieces, you can stay ahead of potential problems, boost performance, and keep services running smoothly. Here’s a quick look at how these elements work together to create a stronger network monitoring strategy:
A centralized monitoring framework
A unified framework consolidates data from fault, performance, and availability monitoring into a single, real-time dashboard. This integrated approach provides IT teams with a holistic view of network health, performance metrics, and availability. By centralizing and visualizing this data in one location, critical issues are less likely to be missed, and troubleshooting becomes significantly faster and more efficient.
Proactive detection and resolution of issues
Integrating fault, performance, and availability monitoring enables organizations to detect and mitigate potential problems before they escalate. For instance, performance monitoring can identify resource utilization trends that may result in faults, while availability monitoring ensures that backup systems are ready to handle potential disruptions.
Deeper insights through cross-pillar integration
When fault, performance, and availability monitoring work in synergy, they deliver more comprehensive and actionable insights. Examples of this collaboration include:
Fault monitoring + performance monitoring: Correlate performance slowdowns with fault alerts to more efficiently identify root causes.
Availability monitoring + performance monitoring: Use uptime and SLA compliance data to optimize resource allocation and sustain peak performance levels.
Fault monitoring + availability monitoring: Leverage dependency mapping from fault monitoring to validate redundancy and ensure failover systems are robust and reliable.
By adopting an integrated approach that unites fault, performance, and availability monitoring, organizations can achieve a more proactive, insightful, and effective network monitoring strategy, ensuring their infrastructure remains resilient and well-prepared to address potential challenges.
Wrapping up
By integrating fault monitoring, performance monitoring, and availability monitoring, you can create a comprehensive strategy that strengthens your infrastructure’s resilience.
This holistic approach ensures that every aspect of your network is continually optimized, empowering you to identify and address issues before they disrupt operations proactively. With a strong focus on maintaining peak performance and reliability, your users will experience seamless, uninterrupted service.
Ready to learn more about building a resilient IT infrastructure? Dive deeper into how to avoid alert fatigue in network monitoring.
1. How do I avoid getting overwhelmed by too many network alerts?
To reduce alert fatigue, implement AI-powered alert correlation and set role-based notifications. This helps group related issues and ensures alerts only reach the people who can act on them, cutting down on noise.
2. What tools help track performance without causing system slowdowns?
Use lightweight agents or SNMP-based polling for performance monitoring. Also, tools that support dynamic baselining help you to detect true anomalies without constantly triggering alerts for normal variations in network traffic.
3. What’s the difference between monitoring latency and availability?
Latency tracks how fast data travels between points, while availability monitoring checks if services are accessible at all. You might have good uptime but high latency, which still creates poor user experience, so you need to monitor both.
4. How can I be sure redundancy systems will actually work when needed?
Regularly schedule failover tests and simulate outages to confirm your redundancy verification processes. Simply installing backups isn’t enough, make sure systems like load balancers or secondary data centers are properly configured and ready to take over.
5. When should I scale my infrastructure based on performance data?
If you notice consistent trends in bandwidth usage, CPU spikes, or memory limits across multiple devices, it’s a sign your network might need scaling. Use predictive analytics to plan upgrades before users start noticing slowdowns.
6. How does dependency mapping help during a network outage?
Dependency mapping shows how systems are interconnected, helping you identify whether a failure is isolated or causing a chain reaction. This speeds up root cause analysis and prevents you from chasing surface level issues instead of solving the real issue.
By Dennis Milholm
Sales Engineer, LogicMonitor
Subject matter expert in IT and Managed Services with 20+ years of experience across NOC operations, product management, and service delivery.
Disclaimer: The views expressed on this blog are those of the author and do not necessarily reflect the views of LogicMonitor or its affiliates.