Your tech stack is growing, and with it, the endless stream of log data from every device, application, and system you manage. It’s a flood—one growing 50 times faster than traditional business data—and hidden within it are the patterns and anomalies that hold the key to the performance of your applications and infrastructure.
But here’s the challenge you know well: with every log, the noise grows louder, and manually sifting through it is no longer sustainable. Miss a critical anomaly, and you’re facing costly downtime or cascading failures.
AI-powered log intelligence isn’t just a way to keep up—it’s a way to get ahead.
That’s why log analysis has evolved. AI-powered log intelligence isn’t just a way to keep up—it’s a way to get ahead. By detecting issues early, cutting through the clutter, and surfacing actionable insights, it’s transforming how fast-moving teams operate.
The stakes are high. The question is simple: are you ready to leave outdated log management behind and embrace the future of observability?
Key takeaways
AI-powered log analysis transforms overwhelming data into actionable insights—far beyond what manual methods can handle.
Static log management can’t keep up with today’s dynamic, multicloud environments—AI adapts in real time.
Organizations that embrace AI-driven log intelligence move from reactive troubleshooting to proactive observability.
Why traditional log analysis falls short
Traditional log analysis methods struggle to keep pace with the complexities of modern IT environments. As organizations scale, outdated approaches relying on manual processes and static rules create major challenges:
Overwhelming log volumes: Exponential growth in log data makes manual analysis slow and inefficient, delaying issue detection and resolution.
Inflexible static rules: Predefined rules cannot adapt to dynamic workloads or detect previously unknown anomalies, leading to blind spots.
Resource-intensive and prone to errors: Manual query matching requires significant time and effort, increasing the likelihood of human error.
These limitations become even more pronounced in multicloud environments, where resources are ephemeral, workloads shift constantly, and IT landscapes evolve rapidly. Traditional tools lack the intelligence to adapt, making it difficult to surface meaningful insights in real time.
How AI transforms log analysis
AI-powered log analysis addresses these shortcomings by leveraging machine learning and automation to process vast amounts of data, detect anomalies proactively, and generate actionable insights. Unlike traditional methods, AI adapts dynamically, ensuring organizations can stay ahead of performance issues, security threats, and operational disruptions.
The challenge of log volume and variety
If you’ve ever tried to make sense of the endless stream of log data pouring in from hundreds of thousands of metrics and data sources, you know how overwhelming it can be. Correlating events and finding anomalies across such a diverse and massive dataset isn’t just challenging—it’s nearly impossible with traditional methods.
As your logs grow exponentially, manual analysis can’t keep up. AI log analysis offers a solution, enabling you to make sense of vast datasets, identify anomalies as they happen, and reveal critical insights buried within the noise of complex log data.
Unlike traditional tools that rely on manual processes or static rules, AI log analysis uses machine learning (ML) algorithms to dynamically learn what constitutes “normal” behavior across systems, proactively surfacing anomalies, pinpointing root causes in real time, and even preventing issues by detecting early warning signs before they escalate.
In today’s dynamic, multicloud environments—where resources are often ephemeral, workloads shift constantly, and SaaS sprawl creates an explosion of log data—AI-powered log analysis has become essential. An AI tool can sift through vast amounts of data, uncover hidden patterns, and find anomalies far faster and more accurately than human teams. And so, AI log analysis not only saves valuable time and resources but also ensures seamless monitoring, enhanced security, and optimized performance.
With AI log analysis, organizations can move from a reactive to a proactive approach, mitigating risks, improving operational efficiency, and staying ahead in an increasingly complex IT landscape.
How does it work? Applying machine learning to log data
The goal of any AI log analysis tool is to upend how organizations manage the overwhelming volume, variety, and velocity of log data, especially in dynamic, multicloud environments.
With AI, log analysis tools can proactively identify trends, detect anomalies, and deliver actionable insights with minimal human intervention. Here’s how machine learning is applied to log analysis tools:
Step 1 – Data collection and learning
AI log analysis begins by collecting vast amounts of log data from across your infrastructure, including applications, network devices, and cloud environments. Unlike manual methods that can only handle limited data sets, machine learning thrives on data volume. The more logs the system ingests, the better it becomes at identifying patterns and predicting potential issues.
To ensure effective training, models rely on real-time log streams to continuously learn and adapt to evolving system behaviors. For large-scale data ingestion, a data lake platform can be particularly useful, enabling schema-on-read analysis and efficient processing for AI models.
Step 2 – Define normal ranges and patterns
With enough log data necessary to see trends over time, the next step in applying machine learning is detecting what would fall in a “normal” range from log data. This means identifying baseline trends across metrics, such as usage patterns, error rates, and response times. The system can then detect deviations from these baselines without requiring manual rule-setting. It’s also important to understand that deviations or anomalies may also be expected or good in nature and not always considered problematic. The key is to establish a baseline and then interpret that baseline.
In multicloud environments, where workloads and architectures are constantly shifting, this step ensures that AI log analysis tools remain adaptive, even when the infrastructure becomes more complex.
Step 3 – Deploy algorithms for proactive alerts
With established baselines, machine learning algorithms can monitor logs in real time, detecting anomalies that could indicate potential configuration issues, system failures, or performance degradation. These anomalies are flagged when logs deviate from expected behavior, such as:
Unusual spikes in network latency that may signal resource constraints.
New log patterns appearing for the first time, which may indicate an emerging issue.
Levels of error conditions in application logs increasing could indicate an outage on the horizon or that performance issues are happening.
A sudden increase in failed login attempts suggesting a security breach.
Rather than simply reacting to problems after they occur, machine learning enables predictive log analysis, identifying early warning signs and reducing Mean Time to Resolution (MTTR). This proactive approach supports real-time monitoring, less outages by having healthier logs with less errors, capacity planning, and operational efficiency, ensuring that infrastructure remains resilient and optimized.
By continuously refining its understanding of system behaviors, machine learning-based log analysis eliminates the need for static thresholds and manual rule-setting, allowing organizations to efficiently manage log data at scale while uncovering hidden risks and opportunities.
Step 4 – Maintaining Accuracy with Regular Anomaly Profile Resets
Regularly resetting the log anomaly profile is essential for ensuring accurate anomaly detection and maintaining a relevant baseline as system behaviors evolve. If the anomaly profile is not reset there is potential that once seen as negative behavior may never be flagged again for the entire history of that log stream. Resetting machine learning or anomaly algorithms can allow organizations to test new log types or resources, validate alerts with anomalies or “never before seen” conditions, and reset specific resources or groups after a major outage to clear outdated anomalies.
Additional use cases include transitioning from a trial environment to production, scheduled resets to maintain accuracy on a monthly, quarterly, or annual basis, and responding to infrastructure changes, new application deployments, or security audits that require a fresh anomaly baseline.
To maximize effectiveness, best practices recommend performing resets at least annually to ensure anomaly detection remains aligned with current system behaviors. Additionally, temporarily disabling alert conditions that rely on “never before seen” triggers during a reset prevents unnecessary alert floods while the system recalibrates. A structured approach to resetting anomaly profiles ensures log analysis remains relevant, minimizes alert fatigue, and enhances proactive anomaly detection in dynamic IT environments.
Benefits of AI for log analysis
Raw log data is meaningless noise until transformed into actionable insights. Modern AI-powered log analysis delivers crucial advantages that fundamentally change how we handle system data:
Immediate impact
Sort through data faster. AI automatically clusters and categorizes incoming logs, making critical information instantly accessible without manual parsing.
Detect issues automatically. Unlike static thresholds that can’t keep up with changing environments, AI learns and adjusts in real time. It recognizes shifting network behaviors, so anomalies are detected as they emerge—even when usage patterns evolve.
Only be alerted to important information. Alerts from logs, like many alerts in IT, are prone to “boy who cried wolf syndrome.” When a log analysis tool creates too many alerts, no single alert stands out as the cause of an issue, if there even is an issue at all. With AI, you can move towards only being alerted when something worth your attention is happening, clearing the clutter and skipping the noise.
Detect anomalies before they create issues. In most catastrophic events, there’s typically a chain reaction that occurs because an initial anomaly wasn’t addressed. AI allows you to remove the cause, not the symptom.
Strategic benefits
Know the root cause: AI doesn’t just flag an issue—it understands the context, helping you pinpoint the root cause before small issues escalate into major disruptions.
Enhance security: Sensitive data is safeguarded with AI-enabled privacy features like anonymization, masking, and encryption. This not only protects your network but also ensures compliance with security standards.
Allocate resources faster and more efficiently: By automating the heavy lifting of log analysis, AI frees up your team to focus on higher-priority tasks, saving both time and resources.
Measurable results
Reduce system downtime. Quick identification of error sources leads to faster resolution and improved system reliability.
Reduce noisy alerts. Regular anomaly reviews result in cleaner logs and more precise monitoring.
Prevent issues proactively. Early detection of unusual patterns helps prevent minor issues from escalating into major incidents.
Stop reacting to problems—start preventing them.
Why spend hours drowning in raw data when AI log analysis can do the hard work for you? It’s smarter, faster, and designed to keep up with the ever-changing complexity of modern IT environments. Stop reacting to problems—start preventing them.
How LM Logs uses AI for anomaly detection
When it comes to AI log analysis, one of the most powerful applications is anomaly detection. Real-time detection of unusual events is critical for identifying and addressing potential issues before they escalate. LM Logs, a cutting-edge AI-powered log management platform, stands out in this space by offering advanced anomaly detection features that simplify the process and enhance accuracy.
Let’s explore how LM Logs leverages machine learning to uncover critical insights and streamline log analysis.
To start — not every anomaly signals trouble—some simply reflect new or unexpected behavior. However, these deviations from the norm often hold the key to uncovering potential problems or security risks, making it critical to flag and investigate them. LM Logs uses machine learning to make anomaly detection more effective and accessible. Here’s how it works:
Noise reduction: By filtering out irrelevant log entries, LM Logs minimizes noise, enabling analysts to focus on the events that truly matter.
Unsupervised learning: Unlike static rule-based systems, LM Logs employs unsupervised learning techniques to uncover patterns and detect anomalies without requiring predefined rules or labeled data. This allows it to adapt dynamically to your environment and identify previously unseen issues.
Highlighting unusual events: LM Logs pinpoints deviations from normal behavior, helping analysts quickly identify and investigate potential problems or security breaches.
Contextual analysis: LM Logs combines infrastructure metric alerts and anomalies into a single view. This integrated approach streamlines troubleshooting, allowing operators to focus on abnormalities with just one click.
Flexible data ingestion: Whether structured or unstructured, LM Logs can ingest logs in nearly any format and apply its anomaly detection analysis, ensuring no data is left out of the process.
By leveraging AI-driven anomaly detection, LM Logs transforms how teams approach log analysis. It not only simplifies the process but also ensures faster, more precise identification of issues, empowering organizations to stay ahead in an ever-evolving IT landscape.
Case Study: How AI log analysis solved the 2024 CrowdStrike incident
In 2024, a faulty update to CrowdStrike’s Falcon security software caused a global outage, crashing millions of Windows machines. Organizations leveraging AI-powered log analysis through LM Logs were able to pinpoint the root cause and respond faster than traditional methods allowed, avoiding the chaos of prolonged outages.
Rapid identification
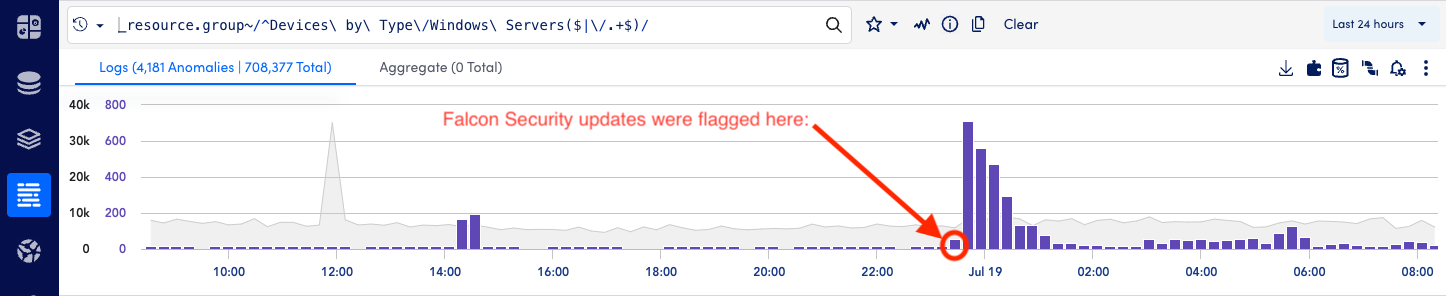
When the incident began, LM Logs anomaly detection flagged unusual spikes in log activity. The first anomaly—a surge of new, unexpected behavior—was linked directly to the push of the Falcon update. The second, far larger spike occurred as system crashes, reboots, and error logs flooded in, triggering monitoring alerts. By correlating these anomalies in real time, LM Logs immediately highlighted the faulty update as the source of the issue, bypassing lengthy war room discussions and saved IT teams critical time.
Targeted remediation
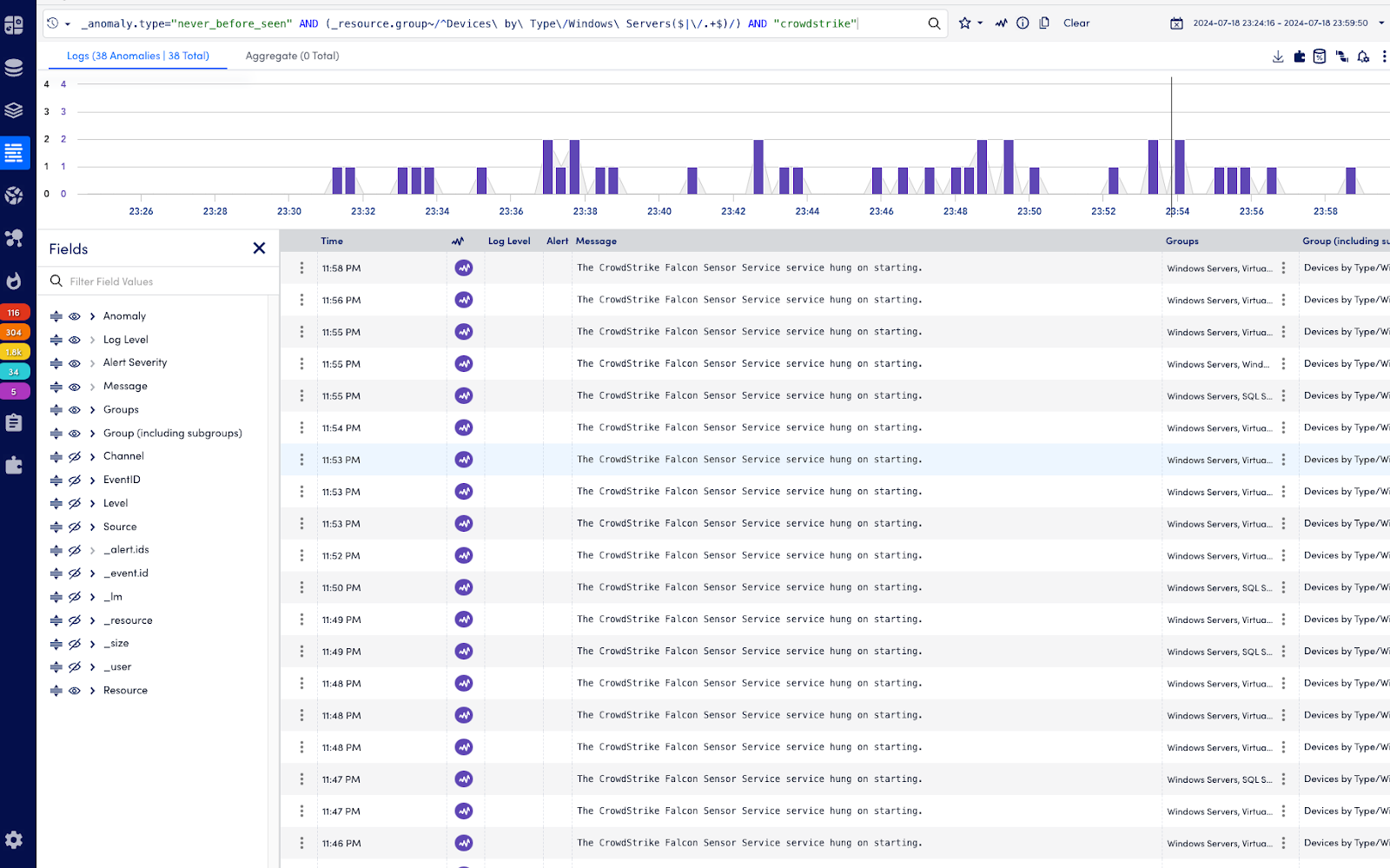
AI log analysis revealed that the update impacted all Windows servers where it was applied. By drilling into the affected timeslice and filtering logs for “CrowdStrike,” administrators could quickly identify the common denominator in the anomalies. IT teams immediately knew which servers were affected, allowing them to:
Isolate problematic systems.
Initiate targeted remediation strategies.
Avoid finger-pointing between teams and vendors by quickly escalating the issue to CrowdStrike.
This streamlined approach ensured organizations could contain the fallout and focus on mitigating damage while awaiting a fix from CrowdStrike.
Figure 1: Windows server log activity showing normal baseline volumes with two anomalous spikes (purple)—an initial trigger from the system update deployment followed by a larger surge of error and reboot events.Figure 2: Detailed log analysis showing “crowdstrike” as the common element across multiple affected servers during the anomaly period, revealing both the scope of the issue and identifying impacted systems.
Learning in progress
One of the most remarkable aspects of this case was the machine learning in action. For instance:
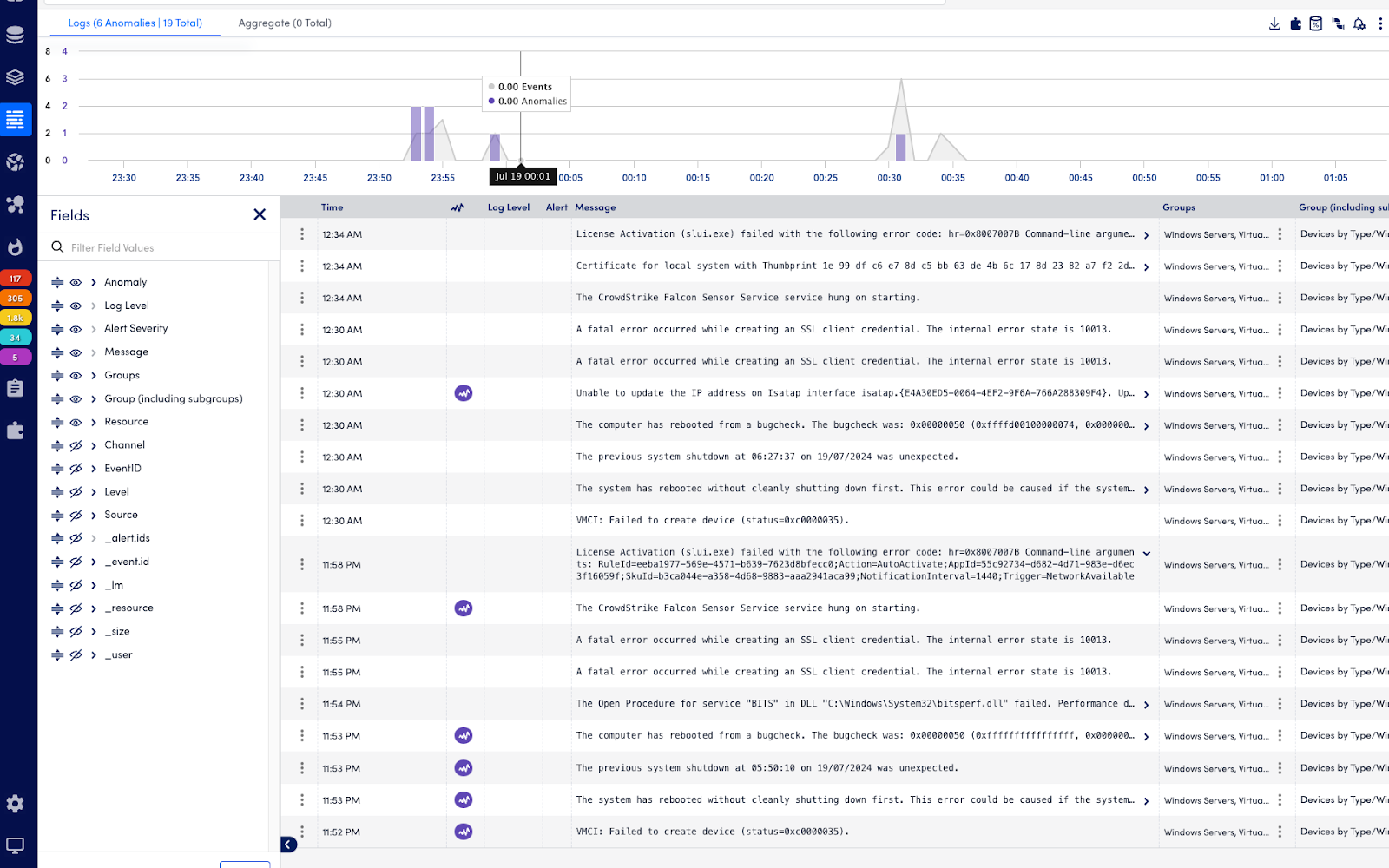
LM Logs flagged the first occurrence of the system reboot error—”the system has rebooted without cleanly shutting down first”—as an anomaly.
Once this behavior became repetitive, the system recognized it as learned behavior and stopped flagging it as an anomaly, allowing teams to focus on new, critical issues instead.
This adaptive capability highlights how AI log analysis evolves alongside incidents, prioritizing the most pressing data in real-time.
Figure 3: Detailed server log view highlighting repeated unclean shutdown events—initially flagged as anomalous but later recognized as learned behavior—demonstrating the adaptive nature of the system’s anomaly detection.
Results
Using LM Logs, IT teams quickly:
Pinpointed the root cause of the outage.
Determined the scope of the impact across servers.
Avoided wasting valuable time and resources on misdirected troubleshooting.
In short, AI log analysis put anomaly detection at the forefront, turning what could have been days of confusion into rapid, actionable insights.
AI log analysis is critical for modern IT
In today’s multicloud environments, traditional log analysis simply can’t keep up with the volume and complexity of data. AI solutions have become essential, not optional. They deliver real-time insights, detect anomalies before they become crises, and enable teams to prevent issues rather than just react to them.
The CrowdStrike incident of 2024 demonstrated clearly how AI log analysis can transform crisis response—turning what could have been days of debugging into hours of targeted resolution. As technology stacks grow more complex, AI will continue to evolve, making log analysis more intelligent, automated, and predictive.
Organizations that embrace AI log analysis today aren’t just solving current challenges—they’re preparing for tomorrow’s technological demands. The question isn’t whether to adopt AI for log analysis, but how quickly you can integrate it into your operations.
By Patrick Sites | AKA "The Logfather"
Product Architect of Logs, LogicMonitor
Subject matter expert in the Log Monitoring space with 25+ years experience spanning Product Management, Presales Sales Engineering and Post-Sales PS/Support Roles.
Disclaimer: The views expressed on this blog are those of the author and do not necessarily reflect the views of LogicMonitor or its affiliates.