

The quick download
Observability shows you what’s happening and agentic AIOps turns that visibility into action.
-
Logs, metrics, and traces surface symptoms, but teams still struggle to correlate signals, identify root causes, and decide what to fix first.
-
Traditional AIOps reduces that noise but still depends on human judgment.
-
Agentic AIOps enriches telemetry with context and orchestrates self-healing workflows.
-
Together, observability and agentic AIOps enable resilient IT operations at scale.
Observability gives IT teams visibility into modern systems, but visibility alone isn’t enough to keep operations resilient.
As environments grow more distributed and complex, IT teams collect more telemetry than ever, yet still struggle to identify root causes, prioritize incidents, and act quickly when issues arise.
The problem here is the gap between seeing what’s happening and knowing what to do about it.
And that’s exactly what AIOps help with.
When paired with observability, AIOps helps teams correlate signals, reduce noise, and turn raw telemetry into actionable insight so incidents are resolved faster and outages are prevented.
In this article, we’ll explore how observability with AIOps works, why traditional approaches fall short, and how agentic AIOps shifts IT operations from reactive firefighting to proactive, intelligent management.
What Is Observability?
Observability is the ability to understand the internal state of a system by analyzing the telemetry it produces, so teams can explain what is happening and why.
Since modern IT environments are distributed, dynamic, and constantly changing, observability makes it impossible to troubleshoot reliably using static thresholds or isolated monitoring data alone.
The Three Pillars of Observability
Observability is built on three core signal types:
- Logs
- Metrics
- Traces
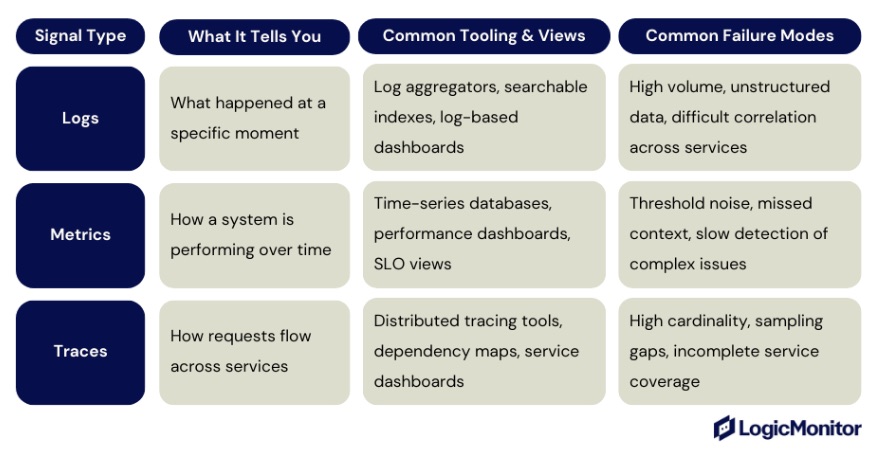
Each pillar answers a different question. So if you rely on only one, it may create blind spots. For example, metrics may reveal a spike in latency, but without logs or traces, you can’t identify the failing component or understand what triggered the slowdown.
Observability Alone Isn’t Enough: The Challenge of Tool Sprawl and Data Overload
Although observability provides visibility into system behavior, it does not automatically interpret signals, identify root causes, or decide what actions to take when something goes wrong.
In complex, distributed environments, that gap between visibility and action is where incidents stall, alerts pile up, and teams fall back into reactive firefighting.
Here’s why:
More Data Doesn’t Mean More Clarity
As IT environments grow in complexity, so does the volume of observability data. Organizations collect an overwhelming number of logs tracking events, metrics measuring performance, and traces mapping service dependencies. Not to mention the amount of unstructured data—such as team conversations and incident reports.
Without the right intelligence to interpret the deluge, these data points become more noise than insight, causing:
- Alert fatigue: When every small fluctuation triggers an alert, IT teams become desensitized, increasing the risk of missing real issues.
- Data silos: Observability tools often work in isolation, making it difficult to correlate logs, metrics, traces, and more across different systems. Without context, troubleshooting becomes a guessing game.
- Limited root cause analysis: Observability rarely connects the dots to pinpoint the underlying cause of incidents. Teams are left investigating symptoms rather than addressing the real issue.
- Reactive problem-solving: Traditional observability tells teams what is happening but rarely provides the “why” behind incidents—forcing teams into a cycle of reactivity.
The problem is transforming those endless streams of data into meaningful, actionable insights.
Suppose an application deployment goes live and minutes later, dashboards light up with elevated latency, rising error rates, and CPU saturation across multiple services.
In this case, logs show scattered warnings, traces reveal slow requests, but across several dependencies.
Observability makes all of this visible.
What it doesn’t do is identify the initiating change, correlate symptoms across services automatically, or determine which alert represents the true root cause.
As a result, your engineers would have to manually connect the dots, decide what to investigate first, and determine how to remediate—all while users are already impacted.
This is the gap between visibility and action, and it’s quite common in large environments. Teams have full visibility into symptoms, but still lose time correlating signals and determining which issue actually caused the outage.
So how do you go beyond raw visibility to real intelligence? Pair observability with AIOps.
Traditional AIOps: Insights Without Action
Artificial Intelligence for IT Operations (AIOps) applies algorithms and machine learning to operational data so IT teams can correlate events, detect anomalies, and identify incidents faster in real time.
Its primary role is to reduce noise, surface patterns humans might miss, and accelerate investigation in complex environments.
Traditional AIOps systems typically support these core capabilities:
- Event correlation: Groups related alerts across systems to reduce noise and highlight incidents that require attention.
- Anomaly detection: Uses algorithms to identify unusual behavior in metrics, logs, and traces that static thresholds often miss.
- Advanced analytics and prediction: Analyzes historical and real-time data to forecast potential failures before they escalate.
- Automated remediation: Executes predefined, rule-based actions such as restarting services or scaling resources when specific conditions are met.
However, this is where traditional AIOps reach its limit.
While it can surface anomalies and patterns, it still relies on predefined rules and human intervention for decision-making. IT teams receive alerts and recommendations but must still determine what actions to take and how to resolve issues, creating bottlenecks and delaying fixes.
Agentic AIOps: Turning Data Overload Into Action
Agentic AIOps takes AIOps to the next level by adapting, learning, and acting in real time to resolve issues before they escalate.
Unlike static rule-based systems, agentic AIOps leverages generative AI for deeper insights and agentic AI for autonomous decision-making. It doesn’t just collect and analyze data; it actively orchestrates responses, transforming raw signals into precise actions that reduce downtime, optimize performance, and ease the burden on IT teams.
What Automated Remediation Looks Like
Agentic AIOps uses AI-powered decision-making to trigger self-healing actions based on real-time signals and context.
Some common remediation playbooks include:
- Restarting or isolating failing services: When application performance degrades due to memory leaks or hung processes, the system restarts affected services or removes unhealthy instances from rotation.
- Rolling back problematic deployments: If errors spike immediately after a release, agentic AIOps correlates the change event and initiates a rollback before impact spreads.
- Scaling resources automatically: During unexpected traffic surges, the system provisions additional capacity to maintain performance without manual intervention.
- Quarantining noisy or unstable hosts: When a single node generates excessive errors or latency, it is isolated to prevent cascading failures across microservices.
- Routing incidents to the right team instantly: Using ownership and service context, incidents are escalated to the correct on-call team with relevant diagnostics already attached.
How Agentic AIOps Improves IT Operations
In day-to-day operations, the impact of agentic AIOps is most visible in the following areas:
- Noise reduction: Agentic AIOps filters out non-critical signals, reducing alert volume by 80% or more, so teams can focus on real threats instead of chasing false alarms.
- Root cause analysis: It correlates signals across systems to pinpoint the exact issue, minimizing manual troubleshooting.
- Proactive response: Agentic AIOps predicts potential failures by analyzing real-time signals and historical trends. It then recommends preventative actions or executes fixes autonomously, from scaling resources to deploying patches before users even notice a problem.
- Comprehensive data integration: Traditional AIOps is limited to logs, metrics, and traces, but agentic AIOps connects a broader dataset—including incident reports, collaboration tool conversations (Slack, Teams, ServiceNow), and historical resolutions. This cross-domain intelligence provides IT teams with more precise, context-aware decision-making.
Agentic AIOps and Observability Work Better Together
As environments scale, 55% organizations pair observability with AIOps.
Why?
Because observability provides the signals, and agentic AIOps turns those signals into prioritized insights and coordinated action, closing the gap between visibility and response.
When combined, they enable IT teams to:
- Resolve issues faster: Observability captures logs, metrics, and traces, while AIOps correlates those signals to identify root causes, reducing investigation time and improving MTTR.
- Enrich context for better decisions: AIOps combines observability data with sources like topology, CMDB, and incident history to provide a clearer understanding of scope, ownership, and blast radius.
- Automate response workflows: Observability highlights where problems occur, and AIOps triggers predefined or adaptive workflows to streamline remediation and reduce manual intervention.
- Improve operational efficiency at scale: Together, they help teams manage growing system complexity without adding tools, dashboards, or headcount.
Accelerates Root Cause Analysis
Agentic AIOps accelerates root cause analysis by connecting symptoms to causes instead of forcing teams to investigate signals in isolation.
A typical RCA flow looks like this:
- Identify the symptom
- Analyze contributing signals
- Determine the probable cause
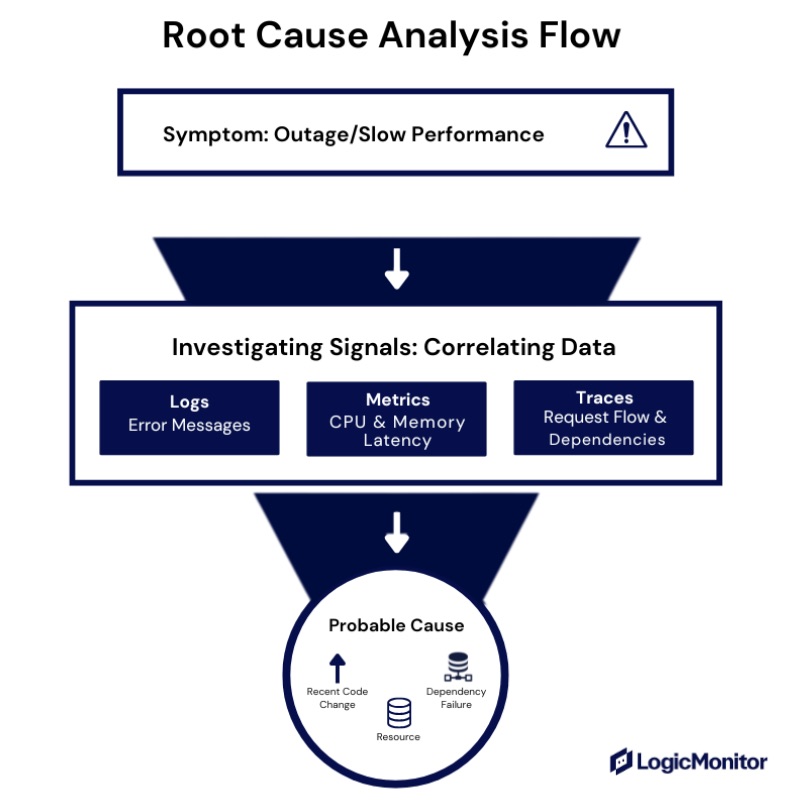
By automating this sequence, you reduce mean time to resolve incidents and limit the duration and impact of outages without manually stitching together data under pressure.
Reduces Tool Sprawl Through Smarter Rationalization
Tool sprawl increases cost and complexity when teams add new observability and AIOps tools without a clear strategy for integration or consolidation.
Agentic AIOps helps teams rationalize their tooling by deciding when to consolidate capabilities and when to integrate existing systems.
When to Consolidate vs. Integrate
- Consolidate tools when multiple platforms collect the same telemetry, generate overlapping alerts, or require parallel dashboards for the same services.
- Integrate tools when specialized systems provide unique data (such as security, networking, or business context) that enhances incident understanding without duplicating pipelines.
Checklist for Reducing Duplicate Pipelines

Key Capabilities to Evaluate in Agentic AIOps
Not all AIOps platforms are designed for autonomous decision-making. So, when evaluating agentic AIOps, look beyond alert reduction claims and focus on how the system reasons, adapts, and operates safely at scale:
- Context-aware reasoning: Can the system correlate telemetry with topology, change events, ownership, and service impact?
- Decision transparency: Does it explain why it recommends or executes an action, so teams can trust and audit outcomes?
- Controlled automation: Can teams define guardrails, approval paths, and blast-radius limits for self-healing actions?
- Learning over time: Does the system adapt based on past incidents and outcomes, or does it rely on static rules?
- Operational integration: Can it work across existing observability, ITSM, and collaboration tools without forcing full tool replacement?
AIOps + Observability = Smarter, More Resilient Systems
Observability alone gives you visibility. AIOps alone gives you insights. But neither is enough on its own. The real breakthrough happens when observability and agentic AIOps work together—turning raw data into real-time, autonomous action.
The future of IT resilience isn’t about collecting more data—it’s about making data work for you. Will your systems stay stuck in reactive mode, or will they evolve to predict, prevent, and self-heal?
The choice is clear: Observability and agentic AIOps are stronger together.




