CRUD and REST are two of the most popular concepts in the API industry. Learn what REST and CRUD are, the basic principles that govern them, and their similarities and differences.
CRUD and REST are two of the most popular concepts in the Application Program Interface (API) industry:
CRUD stands for Create, Read, Update, and Delete, focusing on managing data.
REST, or Representational State Transfer, is a way to design web services that focuses on how clients and servers interact and communicate.
As both work on manipulating databases’ data, it’s easy to see why people are confused about them. This blog will discuss what REST and CRUD are, the basic principles that govern them, and their similarities and differences.
Key takeaways
REST enables stateless client-server interactions, enhancing efficiency with caching and uniform interfaces.
CRUD stands for Create, Read, Update, and Delete, with origins in database management.
REST is broader, providing a standard for data manipulation through HTTP, while CRUD is specific to maintaining records.
REST APIs can include CRUD operations, but REST offers more functionalities beyond CRUD.
What Is REST?
REST is an abbreviation for Representational State Transfer. It is a software architectural style that provides standards for computers on the web, dictating how the systems interact. Roy Fielding, the founder of the REST protocol, defines it as “an abstraction of the architectural elements within a distributed hypermedia system.”
The origins of REST
Before the launch of the REST protocol in 2000, web developers had no standard of how to develop a web API or even use one. Many protocols were used at that time, but they proved too tedious and complicated to carry out. Together with his colleagues, Roy Fielding sought to address this problem and developed what is known today as the REST protocol. The development of REST allowed two servers to exchange data worldwide.
REST-compliant systems are called RESTful systems. These systems are characterized by their statelessness and the separation of client and server concerns. Since its launch in 2000, many companies such as eBay and Amazon have used the REST protocol.
The 5 core principles of REST
REST operates with five basic principles.
1. Independent client-server interaction
The REST protocol allows for independent implementation for the client and the server. This independence means that both parties can make changes without knowing or interacting with one another. Defining what a server and client are is the first step to understanding this principle.
Server: Simply put, servers are machines that provide services to other devices. There are different types of servers, such as boot servers, database servers, print servers, and specialized servers for specific applications. Various applications rely on other applications to deliver a service. For example, a search engine will direct information to its web server. In contrast, a printer on a network will funnel information to the printer server to generate a result.
Client: A client is a remote system that uses services from a server. All the machines connected to a server are called clients. Because some clients have limited disk capacity, they rely on remote file systems to function. Some devices can both be a client and a server at the same time.
The REST protocol allows the two systems to work independently without affecting the result. As long as the client and the server know what format to use when sending messages, different clients eventually reach the same REST endpoints. The client and server interface separation also allows both systems to evolve independently.
2. Stateless communication in REST APIs
RESTful APIs do not cache anything about the HTTP request made on the client side. Not caching means the server treats every session as new and cannot take advantage of any previous information stored on the server. To be genuinely stateless, a server does not store any authentication details of any prior session by the same client. Because a REST API is stateless, a client must provide all the necessary information every session to enable a server to complete a task.
3. Enhancing efficiency with caching
Requests on a server go through different pathways or caches. These caches can either be a local cache, proxy cache, or reverse proxy, and a RESTful API’s server can mark information as either cacheable or non-cacheable. When a client requests their end, this request goes through a series of caches. If any caches along that path have a fresh copy of the representation, it uses that cache to generate a result. When none of the caches can fulfill the request, it returns to the origin server. A RESTful API’s servers determine whether the information is cacheable or non-cacheable.
Caching has several benefits, some of which are:
Reduces bandwidth
Decrease latency by decreasing the number of trips to and from the server to fetch data from memory
Reduces server load
Decreases network failures
4. Predictable interactions via a uniform interface
A system that utilizes the REST API has the client and the server interacting predictably. A resource in the system follows only one logical Uniform Resource Identifier (URI). What differentiates RESTful APIs from non-REST APIs is the uniformity of this interface regardless of the device or application used. Resources on a REST API use Hypermedia as the Engine of Application State (HATEOAS) to fetch related information whenever applicable. All resources on RESTful APIs follow specific guidelines with naming conventions and link formats. A uniform interface follows four guiding principles:
Resource-based: Each resource uses URI as a resource identifier.
Actions on Resources Through Representations: A resource associated with metadata contains information on the server that you can modify or delete.
Self-descriptive Messages: Each message has all the information to describe how it is processed.
Hypermedia as the Engine of Application State (HATEOAS): Clients provide states by body content, request headers, and URI, and the service provides customers with the state by response codes, response headers, and body content. This is called Hypermedia.
5. Leveraged layered architecture for scalability
A RESTful API relies on a layered system to deliver results. This approach allows developers to modularize their systems. For example, see how you can write a custom Terraform provider with OpenAPI to streamline API management. This layered system provides a hierarchy that constrains a layer from seeing beyond its assigned layer and allows the developer to deploy various functions to different servers. Each layer works independently, and each layer does not know the functionality of other layers besides its own. On the user end, a layered system does not allow users to ordinarily differentiate whether they are connected to a primary or intermediary server. The importance of intermediary servers is their ability to provide load-balancing cache sharing.
“Mastering both CRUD and REST is essential for building scalable and efficient web services.”
What is CRUD?: Data management basics
CRUD is an acronym for CREATE, READ, UPDATE, and DELETE. These four database commands are the foundation of CRUD. This acronym is well-known among programmers, but many software developers view it as more of guidance since CRUD was not made as a modern way to create API. After all, its origins are in the database. By its definition, it’s more of a cycle than an architectural system.
Many programming protocols and languages have their own CRUD version with different names and a slight change in what they do. A good example is SQL (structured query language), which uses Insert, Select, Update, and Delete. Also, there are CRUD cycles in a dynamic website, such as a buyer on any eCommerce site (Amazon, Mango, etc.). Users can create an account, update information and delete things from their shopping cart. Other programming languages that use the CRUD frameworks are Java (JOOQ, iBAtis), Phyton (Django), PHP (Propel, Doctrine), and .NET (NHibernate, LLBLGEN Pro), to name a few.
A short history of CRUD
The CRUD acronym was thought to have been created in the 1980s to describe database functionality used by structured query language (SQL). The term first became known in the 1983 book Managing the Data-base Environment by James Martin. The first reference to CRUD operations was in a 1990 article, “From Semantic to Object-Oriented Data Modeling” by Haim Kilov.
The CRUD cycle was designed as a set of functions to enhance persistent storage with a database, which often outlives the processes that started it. In modern software programming and development, CRUD has exceeded its start as a function and lent itself to design principles for applications like SQL, DDS, and HTTP protocol.
The four fundamental operations of CRUD
As discussed above, the four fundamental operations of the CRUD cycle are: CREATE, READ, UPDATE and DELETE.
CREATE: Adds one or more entries and is the equivalent of the Insert function in SQL.
READ: Retrieves data based on different criteria and is equivalent to the Select function in SQL.
UPDATE: Change procedures and modify records without overwriting.
DELETE: Removes one or more specified entries.
L and S: Additions to CRUD
Sometimes, CRUD is expanded to include LISTING (CRUDL). Listing helps prevent more extensive data from being stored in easy memory storage without going to pagination.
Some programmers add an S to CRUD (SCRUD) for SEARCH. Data retrieval is only used for updates and deletions, while software application users sometimes need to search a database for data to see a list of search results
Security considerations for REST and CRUD
APIs enable applications to connect and communicate across networks and the Internet. Since REST and CRUD systems are APIs, these practices can leave cracks if the application isn’t secured effectively. Implementing these practices helps to close gaps and tighten security for your applications, whichever API method you choose.
Authentication and authorization
Implement authentication requirements to ensure only authorized users can access data. The 0Auth2 framework works well for applications and services utilizing REST principles, while role-based access controls work best for CRUD interactions.
Data validation
Implement protocols to ensure all data inputs meet specific criteria, such as file type and format, and that the system removes any potentially harmful data before processing.
Encryption
Use secure HTTP (https) when transferring data and encrypt stored data to ensure it’s not accessible or viewable by unauthorized users.
Rate limiting
Limit the number of requests available for each client to prevent the API from overloading and ensure no client utilizes its share of resources. By gatekeeping API requests, rate limiting also helps guard the server from denial of service (DoS) attacks.
Implementation examples for REST and CRUD
To solidify your understanding, let’s look at how CRUD operations and RESTful services are implemented:
CRUD example using SQL
-- Insert a new user into the 'users' table
INSERT INTO users (name, email) VALUES ('John Doe', '[email protected]');
-- Select a user from the 'users' table where the ID is 1
SELECT * FROM users WHERE id = 1;
-- Update the email of the user where the ID is 1
UPDATE users SET email = '[email protected]' WHERE id = 1;
-- Delete a user from the 'users' table where the name is 'John Doe' and the email is '[email protected]'
DELETE FROM users WHERE name = 'John Doe' AND email = '[email protected]';
Using the example graphic above, the CRUD steps outlined in the graphic perform the following functions using SQL.
Create: In this step, the command inserts a new record into the users table of the database named John Doe with an email address of [email protected].
Read: This command retrieves the record for viewing from the users table with the value of 1 in the id column of the SQL table.
Update: This line overwrites the information in the ’email’ column of the record with an ‘id’ value of 1 with the email address [email protected].
Delete: This command deletes an erroneous record from the database in which the name was entered as ‘John Doo’ with the same email address.
REST example using HTTP methods
# Create a new user (POST request)
POST /users
{
"name": "John Doe",
"email": "[email protected]"
}
# Retrieve user information by ID (GET request)
GET /users/1
# Update user information (PUT request)
PUT /users/1
{
"email": "[email protected]"
}
# Delete a user by ID (DELETE request)
DELETE /users/1
In the example graphic above, these REST commands perform the following tasks:
POST: The POST /users request creates a user incident with the name value “John Doe” and the email value “[email protected].”
PUT: The PUT /users/1 request updates the email value in the incident with the ID of 1 to “[email protected].” This example assumes the John Doe record has the ID of 1.
Practical use cases for REST and CRUD
While engineers often use the two systems together in a REST-CRUD combination, each has its own strengths for practical use when building applications and services.
REST is meant for interactions between clients and stateless servers. This concept works well for public APIs such as social media applications, streaming services, and online banking. REST is also ideal for developing interoperable systems like microservices and Internet of Things (IoT) applications.
CRUD is suitable for basic data-management applications, such as simple CMS editors, interactive calendars, and event management applications. It’s also ideal for building applications and tools that require direct data manipulation, including internal applications such as admin dashboards and inventory management systems.
“CRUD focuses on data operations, while REST defines how web services communicate.”
What are the similarities between CRUD vs. REST?
Some purists may argue that REST and CRUD are in no way related. However, a closer look at their commands reveals similarities.
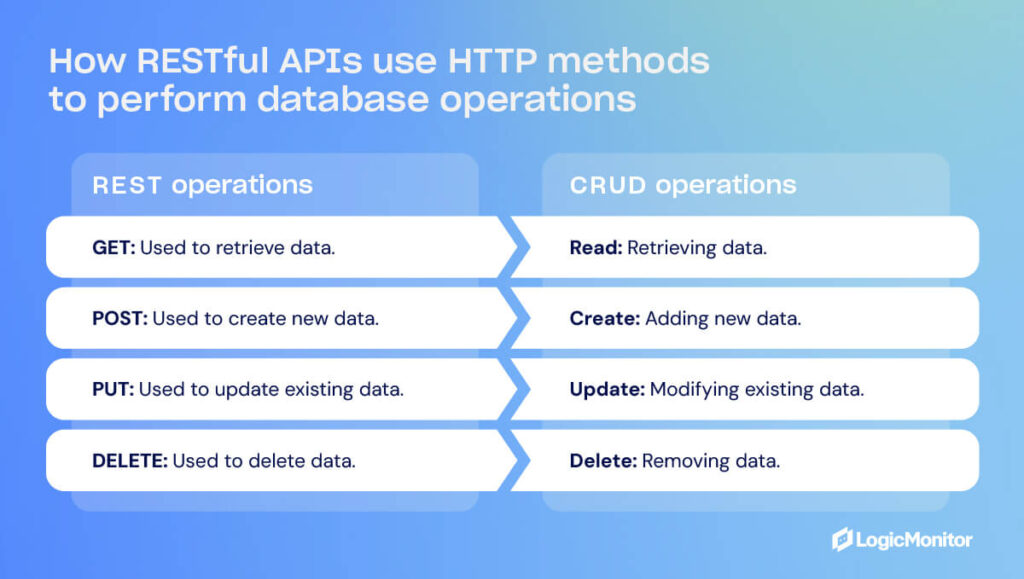
REST Commands
POST: This creates a new record in the database.
GET: This request reads information sourced from a database.
PUT/PATCH: This updates an object.
DELETE: This removes a record from the database.
CRUD Commands
CREATE: This creates a new record through INSERT statements. In REST, this is a POST command.
READ/RETRIEVE: These procedures grab data based on input parameters. In REST, this is equivalent to a GET command.
UPDATE: This updates data without overwriting it. In REST, this is a PUT request.
DELETE: This removes data from the database. REST uses the same request to delete data.
What are the differences between CRUD vs. REST?
Because of their similarities, it’s easy to mistake REST and CRUD for having the same function. But that’s far from the truth. Diving a little bit deeper explores their differences.
REST is an architectural system centered around resources and Hypermedia using HTTP commands. CRUD is a cycle meant to maintain records in a database setting. In its base form, CRUD is a way of manipulating information and describing an application’s function. REST is a way of controlling data through HTTP commands. It is a way of creating, modifying, and deleting information for the user.
CRUD functions can exist in a REST API, but REST APIs are not limited to CRUD functions. CRUD can operate within a REST architecture, but REST APIs can exist independently of CRUD. For example, a REST API can allow clients to reboot a server even if it doesn’t correspond to any CRUD functions. REST can do this as long as it uses the proper HTTP methods.
REST usually refers to using data through HTTP commands. It’s a dogma that facilitates how users manipulate data onscreen and save the information on the server. Programmers can create a REST API that can handle the essential CRUD functions, but the same can’t be said the other way around.
The functions of REST and CRUD are similar (as discussed above), but they are not the same. PUT replaces a resource, even one that doesn’t exist yet. POST adds a new resource. Both of these commands create a new resource, but PUT is usually used to update resources that are already there. PATCH is mainly used to update a part of a resource, but PUT is used only to update an entire resource by replacing it.
“CRUD focuses on data operations, while REST defines the architecture for web services, shaping how clients and servers interact.”
REST and CRUD work together, but they are not the same
REST and CRUD work together because CRUD can exist within a REST environment, and their functions often correspond to each other, but they are not the same. The best way to differentiate between them is to remember that REST is a standard (an API architecture), and CRUD is a function. Understanding this essential but straightforward difference is necessary for understanding both.