

In this article




Redis (Remote Dictionary Server) is a remarkably fast NoSQL key-value data structure server developed by Redis and written in the ANSI C programming language. Redis performs in-memory caching, meaning data structure stores can be saved and recalled much more nimbly than with a traditional database. In addition to its speed, Redis compression can also easily support a wide range of abstract data types, making it incredibly flexible for almost any situation.
At LogicMonitor, we focus on large volumes of runtime series data, monitoring customer devices at regular intervals for our agentless application. Recently, we’ve integrated machine learning to improve anomaly detection by developing a stateless microservice that interprets data streams and provides meaningful analytics. While essential, this process generates significant data that must be stored and accessed efficiently, which is where Redis comes in.
Key takeaways

Native Redis data compression compression capabilities
While Redis excels in speed and flexibility, it does not natively compress the data it stores. By default, Redis stores data in its raw format (uncompressed), which is highly efficient for snappy retrieval and processing but can lead to increased memory usage, especially when dealing with large volumes of data, such as time series or large datasets in JSON format.
Why manual compression techniques are necessary
Given Redis’s lack of built-in compression, manual compression techniques become essential for optimizing memory usage and reducing storage footprint. These techniques allow you to compress data before storing it in Redis, thereby significantly reducing the amount of memory consumed and improving the efficiency of data storage. This is particularly critical in environments like ours, where high data throughput and storage efficiency are paramount.
By applying manual compression strategies, such as those discussed later in this article, you can leverage the speed of Redis while mitigating the memory consumption typically associated with large-scale data storage.
Redis’s lack of built-in compression makes manual strategies essential for managing large-scale data efficiently.
Example state model
To persist machine learning training data for our various algorithms across several pods in our environment, we maintain a model in JSON format. This model is cached in centralized Redis clusters for high availability. Below is a simplified example of this model.
{
"resource-id-1 ": {
"model-version" : string,
"config-version": int,
"last-timestamp": int,
"algorithm-1-training-data": {
"version" : string,
"training-data-value": List[float],
"training-data-timestamp": List[float],
"Parameter-1" : float,
"Parameter-2" : float
},
"algorithm-2-training-data": {
"version" : string,
"training-data-value": List[float],
"training-data-timestamp": List[float],
"Parameter-1" : float,
"Parameter-2" : float
},
......
}
}Compression Strategies
LZ4 Compression
By default, Redis does not compress values it stores (read more here), so any size-reduction would have to be performed on the application side first. We found that the storage and network throughput savings achieved through any of our manual compression options were worth the additional processing time.
At first, we elected to utilize LZ4 because of its speed and ease of integration with the existing codebase. The introduction of lossless compression immediately reduced the overall storage size from approximately 39,739 bytes to a much more manageable 16,208 bytes (60% savings). Most of these savings can be attributed to the statistical redundancy in the key-values of our model.
Reducing Noise Before Compression
As our project grew in complexity, we needed to include additional longer float value lists. Because of this, our training data model more than doubled in size and now mostly consisted of seemingly random numerical data that lessened its statistical redundancy and minimized compression savings. Each of these float values had large decimal precision (due to the double-precision default in Python), which translated to considerably more bytes when setting to Redis as a string. Our second strategy was to round decimal precision with two different options. This is detailed below.
Rounding Option 1 (All Values)
- Round all float values to 4 decimals of precision.
Rounding Option 2 (Based on 5th Quantile Value)
- Round float values to 0 decimals if value is above 100, (e.g. 54,012.43 → 54,012)
- Round float values to 1 decimals if value is between 1-99, (e.g. 12.43 → 12.4)
- Round float values to 4 decimals if value is less than 1 (e.g. 0.4312444 → 0.4312)
Option 1 Result: ~80,000 bytes reduced to ~36,000 bytes (55% savings)
Option 2 Result: ~80,000 bytes reduced to ~35,000 bytes (56% savings)
Option 1 was selected as it saved approximately the same level of memory without the added complexity and reduced decimal precision. We also verified that losing the precision impact on the algorithm was insignificant.
Compression With Encoding – 85% Savings!
While rounding dramatically reduced our Redis storage, consumption was still high and we lost a margin of accuracy in our algorithm’s calculations.
Before converting to Lists, the float value arrays exist as Numpy N-dimensional arrays (ndarray). Each of these arrays was scaled down to float16 values and encoded in Blosc with the internal ZLib codec. Blosc can use multithreading and splits the data to compress in smaller blocks, making it much faster than traditional compression methods.
The resulting compressed array is then encoded with Base64 and decoded to 8-bit Unicode Transformation Format (UTF-8) before being dumped to JSON. The resulting Redis storage size was reduced down to 11,383 bytes (from ~80,000 bytes), a dramatic improvement from what was achieved by either compressing exclusively with LZ4 or compression with float decimal rounding.
Ultimately, compression with encoding was the strategy included in the final iteration of our anomaly detection program. Combining the two strategies saved 85% of memory consumption.
Manual compression in Redis can slash storage requirements by up to 85%, dramatically improving system efficiency without sacrificing performance.
Monitoring While Benchmarking
During compression testing, we utilized some of our out-of-the-box Redis modules to monitor performance for all Get and Set transactions. Comparing transmission results to Redis with and without prior compression demonstrated substantial elapsed time improvements.
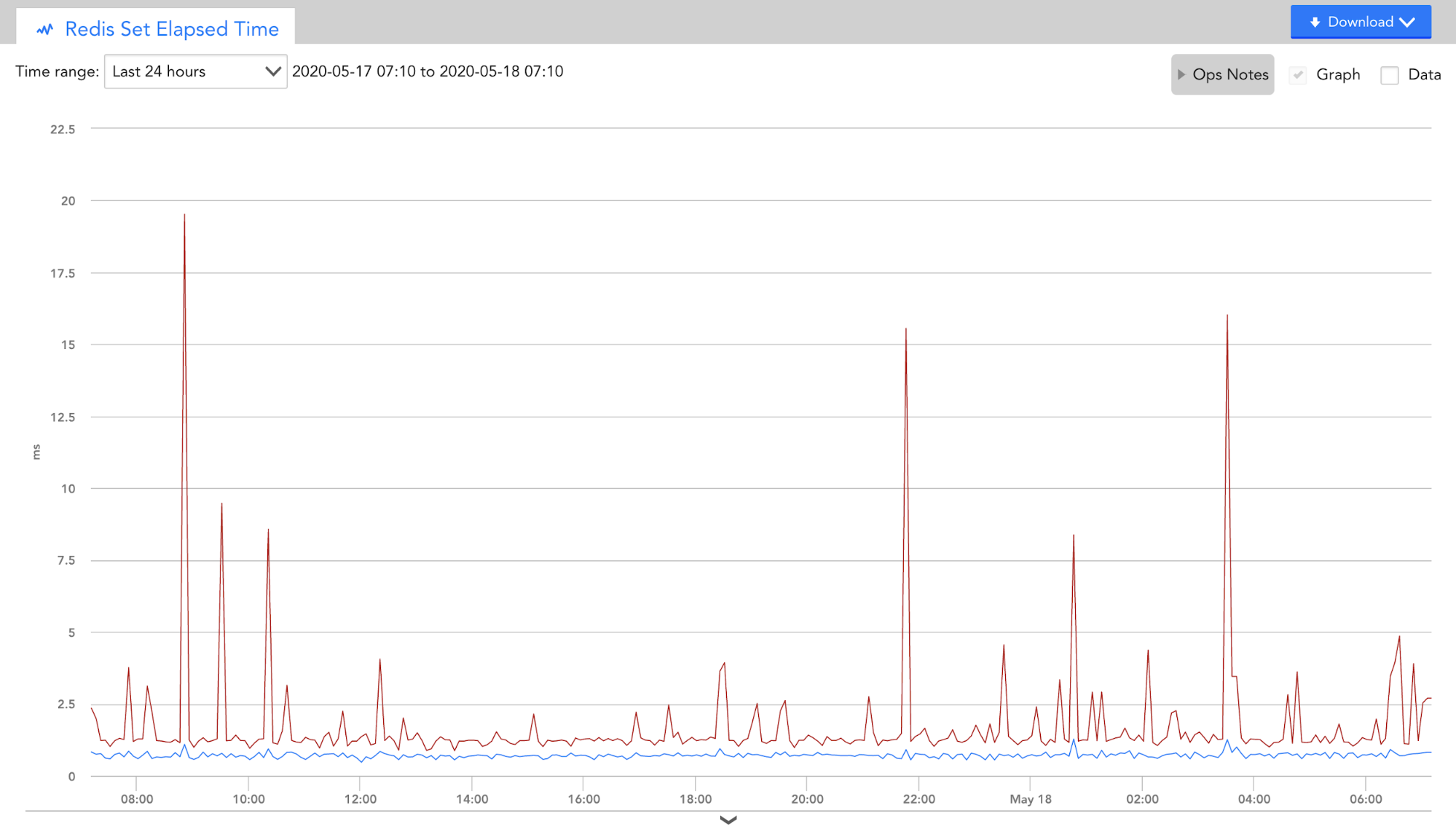
Redis compression: Key challenges and best practices
While compression offers substantial benefits in reducing Redis’s storage footprint, it is not without its challenges. Implementing compression in Redis can introduce potential pitfalls that, if not managed carefully, could impact performance and data integrity. Below, we outline some of these challenges and provide strategies to mitigate them.
1. Performance degradation during peak loads
Compression, by its nature, requires additional CPU resources to encode and decode data. During periods of peak load, this can lead to increased latency and reduced throughput, particularly if the compression algorithm used is resource-intensive.
How to avoid it:
- Opt for fast, lightweight compression algorithms like LZ4 when dealing with high-throughput use cases.
- Consider hybrid approaches where only certain data types or less frequently accessed data are compressed.
- Regularly monitor system performance and adjust compression settings as needed to maintain an optimal balance between compression efficiency and performance.
2. Data corruption risks
Compressed data, especially when using more complex encoding methods, can be more susceptible to corruption, especially if decompression also happening. If a single bit in a compressed block is altered, it could potentially render the entire block unreadable, leading to data loss.
How to avoid it:
- Implement robust error-checking mechanisms and backups to ensure data integrity.
- Use compression algorithms that include built-in error detection.
- Regularly test and validate compressed data to catch and correct errors early.
3. Difficulties in scaling
As your Redis database grows, managing compressed data can become increasingly complex. The added layer of compression requires careful scaling strategies to ensure that data retrieval times remain consistent and that the system remains responsive.
How to avoid it:
- Plan for scalability by designing your compression strategy with growth in mind.
- Utilize Redis’s clustering capabilities to distribute the load and ensure that compression does not become a bottleneck.
- Continuously monitor and optimize your compression strategy to adapt to changes in data volume and access patterns.
About LogicMonitor
LogicMonitor is the only fully automated, cloud-based infrastructure monitoring platform for enterprise IT and managed service providers. Gain full-stack visibility for networks, cloud, servers, and more within one unified view.




Subscribe to our blog
Get articles like this delivered straight to your inbox