Collector Monitoring
Last updated - 09 June, 2026
LogicMonitor Collector is at the core of monitoring your systems. To ensure consistent performance, you must monitor your Collectors to keep up with data collection load and minimize disruption when a Collector goes down. This includes sending timely notifications to recipients.
Monitoring your Collector involves the following:
- Collector Monitoring Setup
- Collector Downtime Event Alerting
Requirements for Monitoring Collector
To monitor a Collector, you need the following:
- Collector DataSources with the Collector prefix.
- A Collector configured with the Monitor the device on which the collector is installed switch enabled and a resource group specified for it.
For more information, see Adding Resources.
Collector Monitoring Setup
Collector monitoring can be set up in the following two ways:
- Collector Host Monitoring
- Collector Performance Monitoring with Collector DataSources
Collector Host Monitoring
You must add the resource on which the Collector is installed for monitoring. This enables you to monitor CPU utilization, disk space, and other metrics important for smooth Collector operations. For more information, see Adding Resources.
Collector Performance Monitoring with Collector DataSources
LogicMonitor provides a series of built-in Collector DataSources that provide insights into Collector operations, performance, and workload. Collector DataSources are automatically applied to the Collector device when you add the resource to monitoring. To verify if Collector DataSources are applied, expand the resource in the Resources tree and search for the Collector DataSource group.
If Collector DataSources are not automatically applied to the resource, you can manually add the value of Collector to the system.categories property of the resource. For more information, see Resource and Instance Properties.
LogicMonitor indexes the resource as the host of a Collector and automatically applies the Collector DataSources to it. You can configure alerts to warn you when the Collector performs poorly.
Note: Collector DataSources only monitor the preferred Collector set in the resource configurations. The preferred Collector must be installed on the resource.
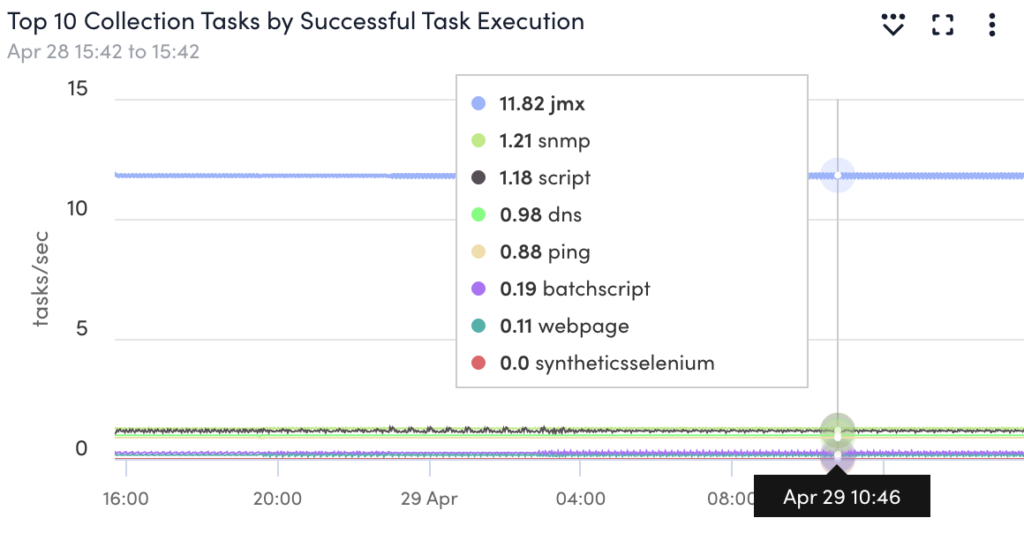
The Collector Data Collecting Tasks monitors statistics for collection time, run time, success or failure rates, and the number of active collection tasks. One of the overview graphs available for this DataSource features the top ten tasks contributing to Collector load for identifying the source of CPU or memory usage.
Collector Downtime Event Alerting
A Collector is considered down when LogicMonitor servers do not hear from it for three minutes. To minimize downtime and mitigate the risk of monitoring interruption, ensure that Collector down alerts are actively delivered using email, text message, and other notification methods to individuals in your organization. These alerts also display in the LogicMonitor user interface.
Important: When a Collector goes down, alerts triggered by resources monitored by that Collector before the Collector went down remain active but new alerts are not generated while the Collector is down. However, devices that do not fail over to another Collector ignore the alert generation suppression and may generate Host Status alerts while the Collector status is down.
The following settings on the Manage Collector page configure routing for Collector down alerts:
- Collector Down Escalation Chain—An escalation chain defines who receives alert notifications, how notifications are delivered, and the order in which recipients are notified. For more information, see Escalation Chains.
- Send Collector Down Notifications—Set the resend interval for Collector down notifications. You can notify only once (no resend) or you can specify the time interval that must pass before the Collector down alert notifications are escalated to the next stage in the escalation chain. If an alert has reached the final stage or there is only one stage specified in the escalation chain, then this interval determines how often the alert notification is resent until it is acknowledged or cleared.
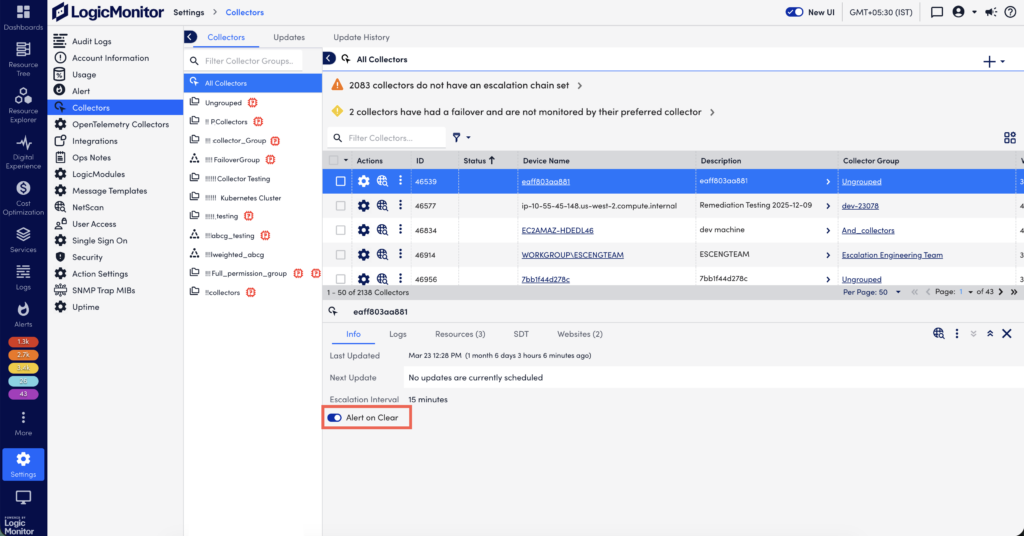
Note: By default, the Alert on Clear switch is enabled for automatically delivering notifications to all escalation chain recipients when a down Collector becomes online. If the Collector’s designated escalation chain routes alert notifications to LogicMonitor integration, do not disable this option. For more information, see Alert Rules and Escalation Chains.